放弃“千行代码缺陷率”吧

作者:王洪亮/大锤
千行代码缺陷率是一个很常用的统计质量的指标。十几年前是一个非常通用的参考指标。
时至今日,仍然有很多组织在用这个指标作为质量的参考依据。
那么什么是千行代码缺陷率呢?下面这个公式解释了千行代码缺陷率的构成。
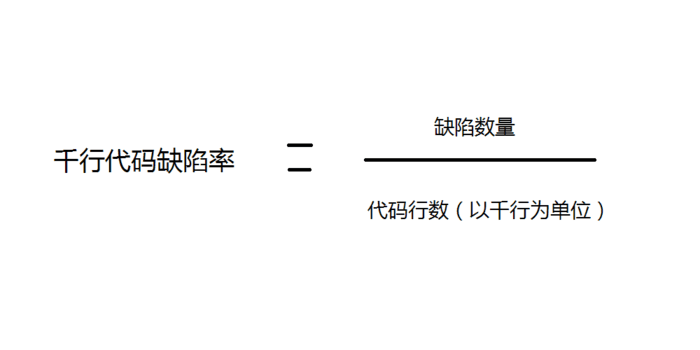
按照上述的公式来看,缺陷的数量越少表示质量越高。而生产的代码越多,可以容忍的bug数量也就越多。那么这个公式应该是可以很好地检测代码质量的。
然而,事情并不是这么简单的。看事情要从多个角度来看。让我们站在程序员的角度来看看这个事情是什么样的吧。
小明(为毛总是他)是一个很挫的程序员,基本上他的工作就是每天生产bug。他左边的小刚是个很优秀的程序员,他每天的工作就是如何使得代码更精炼,提高代码的可读性,可扩展性和可变更性。他右边的小美是个很上进的程序员,每天都在努力的想要学习小刚那种优雅的写代码的方式。
一个周期下来,公司开始考核质量了。
小明在这期间总共写了2万行代码。其中留到测试发现bug数量有162个,符合公司对于质量的预期,每千行代码的bug数7-10个。小明得到了赞赏。
小刚在这期间总共写了4000行代码,其中留到测试发现的bug数量为12个,远远低于公司对于bug的虚荣范围。负责测试他的代码的人被责令要继续加强测试。
小美在这期间写的代码行数也是4000行。其中留到测试发现的bug数量有53个,超过了公司的质量预期范围,属于差的一等。小美被责令改进代码质量。
他们的质量状况统计如下:

为什么事实和理想之间的差距这么大?小刚是个优秀的的程序员用4000行代码实现了小明用20000行代码实现的功能。并且通过自己的自动化测试,使得质量得到有效的保证,但是却得到了一个“测试不充分”的评价呢?
为什么努力像小刚一样写优秀代码的小美得到了一个差评呢?
那么之后他们的行为又会由于得到这样的不公正的待遇走向何方呢?
没过多久,需求发生了变更。小刚和小美的代码具有充分的柔软性,可以很优雅的应对变更。
并且没有引入新的问题。而小明写的意大利面条式代码(Spaghetti Code),则由于复杂性提高,而引入了新的上百个Bug。但是由于代码规模大,所以在原来的考核标准下,小明仍然得到了好评。而小刚和小美则继续得到中评或者差评,因为他们的工作看起来太简单了。
很显然,这个指标已经不能够正确的反映质量状况了。那么到底是什么地方出了问题?又应该如何改正呢?
首先,这是个目标和方法背道而驰的指标。
程序员短期之内水平飞速提升的可能性基本上不存在,而作为程序员面临这个公式的最佳策略是稀释代码。下面是程序员的策略图
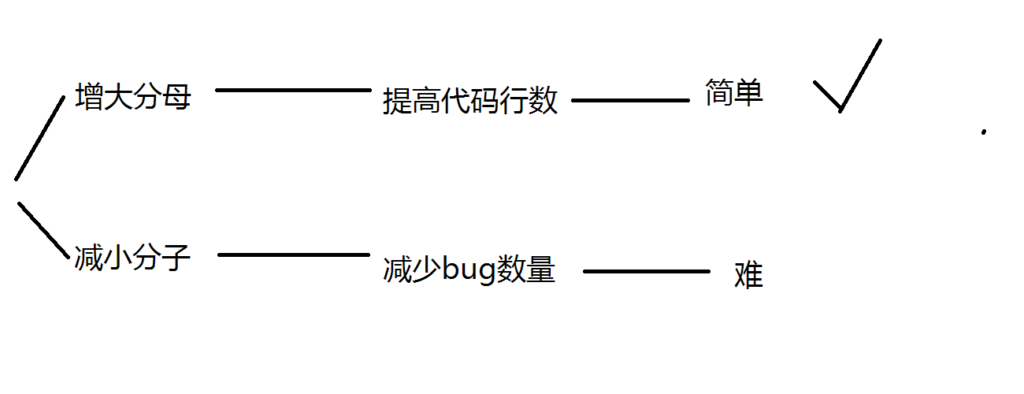
所以,选择稀释代码是个最简单的策略。那么稀释代码的最佳策略是什么?复制粘贴
复制粘贴的最大问题是什么?引入更多的bug(请参考DRY原则 )。为了能够提高质量的最佳策略竟然是引入更多的问题!这就是这个指标带来的问题之一。
问题之二是,这个指标带来的隐含意思是,向团队宣布:我们不欢迎那些程序写的好的程序员。
就像上例所提到的,写的好的小刚,和正在努力写得好的小美都得不到好评。至于那个无稽的7-10个/千行的指标(这个数字是被广泛使用的一个数字)更是莫名其妙。这个的潜在意思是“我不相信你能够写出来高质量的代码”。WTF??
问题之三是强凑Bug。当QA团队也要面临这个指标考核的时候,他们会怎么做?一个bug拆开写,同一个原因的bug分开记录,这样可以凑到这个指标区间,来粉饰数据。
这些假数据对于决策有什么帮助呢?
同样的,千行代码生产率这个指标,也需要放弃。
这背后的最重要的原因就是:
功能的多少和代码行数不成正比关系,甚至也不呈现正相关关系。
比如,我写的一套Java代码框架,允许定义页面的操作为空白。
比如:
@Controller
@RequestMapping(“/books”)
public class BookController extends CrudBaseController {}
就可以完成对图书的增删改查操作。
增加一组新的功能,只要几行代码而已。有的时候增加新功能甚至是需要减少代码行数的。
所以,凡是以代码行数来统计什么的指标都是不可靠的。
有人会说,我们的公司不会有人故意稀释代码,所以代码行数在我们这里是可以使用的指标。
这个推论并不成立。因为代码行数和质量并无任何直接关系。这就好像是扔砖头看风向一样。自欺欺人而已。
那么,说了这么多,不这么考核质量,怎么考核质量呢?有几个常用的可靠指标,推荐给大家:
1. 圈复杂度(Cyclomatic Complexity)
简单的说圈复杂度越高的代码会有越多的Bug,这个是业已被证明了的。圈复杂度反应了代码的耦合度。都要写低耦合高内聚的代码,那么这个指标就可以帮助更好地了解代码的耦合度情况。
推荐的圈复杂度不要超过10,如果实在做不到,那么不要超过20。
如果你的团队代码的圈复杂度已经超过100了,你可能需要考虑些大动作了。
测量圈复杂度的工具也有很多。下面推荐几个:
- Source Insight
- Code Metrics
- Cobertura
2. 平均缺陷修复时间(Mean Time To Repair)
发生缺陷并不可怕,可怕的是修复的时间过长。假设每个缺陷修复时间只要几分钟,那么有几十个Bug,修复的总计时间也并不会太长。而平均一个Bug修复需要3天的那种(其中2天都在调查问题根源),基本上代码扔掉重写的成本都会比在补丁上继续打补丁的成本要低得多。
平均缺陷修复时间能够更好地反映代码本身的质量状况,以及团队的成熟程度。
往往平均修复时间较长的代码都是复杂度高,耦合度高的代码。而平均修复时间短的代码都是结构相对清晰,命名规范,容易理解,扩展和变更的代码。
如果你的公司还在使用“千行代码缺陷率”,你把这篇文章转给相关人员看看吧。



 EN
EN

{kind=link}
{kind=link}
{kind=link}