TDD(测试驱动开发)示范姿势(上)

SAFe:管理的幼稚主义
2019年9月18日
TDD(测试驱动开发)示范姿势(下)
2019年9月29日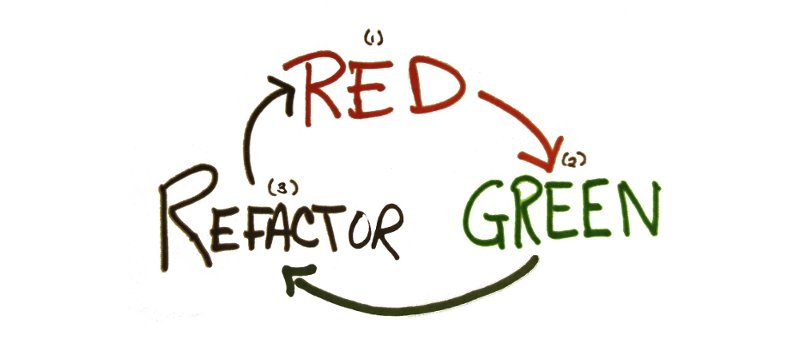
前言
目录
写给想要上手试试 TDD,却不知从何入手的同学。
本文假定你已经对 TDD 有一些基本的了解,如果你不知道 TDD 是什么,可以先看看文末参考链接 [1] 的介绍文章。
TDD 号称有很多好处,但是这些好处有些看不见摸不着;而 TDD 让你多写了很多(测试)代码,这确是实打实的。所以,这玩意儿到底值不值得让你多花这些功夫呢?本文采用 JavaScript 语言,以一道常见的 TDD 练习题为例,完整演示整个编码和思考过程。最后你会得出“真香”的结论。
这是一个三部曲文章的第一篇,后面会分别有一篇后端示范和一篇前端示范,分别介绍笔者如何在实际项目的后端和前端代码中做 TDD。
理解需求
原始需求描述在这里:http://codingdojo.org/kata/Args/ 。
命令行参数
由于有些同学可能对命令行参数的概念不是很熟悉,在这里用一个例子来解释一下,熟悉此概念的同学可以跳过本节。
假设有个网络服务器程序,程序的文件名是 webserver,需要你去启动一下。那么你该怎么做呢?打开一个终端命令行工具,直接输入 webserver,然后回车,就启动起来了。
如果这个程序默认监听 80 端口,而你希望让他监听 8080 端口,该怎么做呢?你需要通过一个命令行参数去“告诉”这个程序,于是,启动命令就是 webserver -p 8080。这里的 p 就是单词 port——端口——的缩写,-p 8080 就可以理解为“以 8080 作为 p(ort) 启动”。
如果你希望让它在后台执行,就可以通过 -d 参数“告诉”它,启动命令就是 webserver -d。这个 d 就是单词 daemon——守护进程——的缩写,-d 就是“以 d(aemon) 方式启动”。
如果你希望它把日志文件存放在 /usr/logs 目录,那么可以使用 -l 参数,于是启动命令就是 webserver -l /usr/logs。这个 l 是单词 logs——日志——的缩写,-l /usr/logs 就是“把 l(ogs) 放在 /usr/logs 这个位置”。
最后,如果你希望让这个程序启动的时候在后台运行,并且监听 8080 端口,同时将日志文件放在 /usr/logs 目录,那么你就会这样启动它:webserver -d -p 8080 -l /usr/logs。
现在问题来了,假设这个 webserver 是你写的,你怎么知道别人启动程序的时候,“告诉”了你哪些参数呢?以刚才的 webserver -d -p 8080 -l /usr/logs 启动方式为例,你可以访问某个系统变量,这个系统变量是一个字符,里面存放的就是 "-d -p 8080 -l /usr/logs" 这一串内容。以此类推,如果启动命令是 webserver -p 3000,那么这个系统变量里面存的就是 "-p 3000"。这个系统变量,就叫做命令行参数。
题目实际需求
然后就是这道题的需求:你需要做一个命令行参数解析器。如此一来,不同的应用程序开发者,都可以重用这个工具类,来做命令行参数解析,而不需要重复造轮子。这个解析器,从形如 "-d -p 8080 -l /usr/logs" 的字符串命令行参数中,提取出“需要后台运行”、“监听的端口是 8080”以及“日志目录是 /usr/logs”这样的信息,以供应用开发者使用。
这个解析器需要是通用的,比如作为 grep 这个程序的开发者,需要接受的参数有 -E、-i、-v、-n 等等几十个参数。解析器需要“知道”这些参数的定义规则才能进行解析。所以这个解析器除了接受字符串命令行参数,还需要接受一个规则信息。这个规则信息是应用程序开发者,也就是解析器的使用者传给解析器的。规则信息中指明了有哪些参数需要解析,以及各个参数的数据类型,比如整数、字符串、布尔。
解析器完成解析后,应用程序可以向解析器询问一个参数的具体数值。对于 "-d -p 8080 -l /usr/logs" 这个命令行参数,如果询问 p 参数的值,就应该得到 8080 这个数字;询问 d 参数的值,就应该得到 true 这个值(即有传入这个参数);询问 l 参数的值,就应该得到 "/usr/logs" 这个字符串。返回的参数值的类型,必须符合规则定义中指定的类型。
如果规定中指定的某个参数,没有在命令行参数中出现,则询问相应参数的值的时候,应该得到对应类型的默认值。即,布尔型参数的默认值是 false,整数型参数的默认值是 0,字符串型参数的默认值是 ""。
除此以外,如果传入的命令行参数中出现了规则里未定义的参数,则应该抛出错误,并且提供友好的错误提示,告知用户是什么地方出了错。除了未定义的参数,还有诸如类型不匹配,数据未指定等错误类型需要处理。
以上需求达成后,如果你有雄心(原文这么说的),可以考虑对列表型参数的支持,例如 -g this,is,a,list -d 1,2,-3,5 这个命令行参数,可以解析出参数 g 的值是 ["this", "is", "a", "list"],而 d 参数的值则是 [1, 2, -3, 5]。
另外,请确保你的代码具备良好的扩展性。也就是说,应该可以很容易的加入新的参数类型,而不需要对已有的代码逻辑做修改。
用代码描述需求
我们为什么要写代码?为了实现需求。所以,写代码的时候,一定要从需求方(用户)的角度去考虑,别人会怎么使用我们这段代码?准确的说,在你动手写任何实现之前,就要从这个角度开始考虑,这样才有可能尽量避免写出不符合需求的代码。
那么,别人会怎样使用我们的参数解析器呢?根据需求描述,别人应该会创建一个解析器的实例,传入规则定义,以及命令行参数字符串,并返回解析结果,大概是这么个样子:
let parser = new ArgumentParser(schemas);
let commandLine = '-d -p 8080 -l /usr/logs';
let result = parser.parse(commandLine);
也就是说,我们需要写一个 ArgumentParser 类,它的构造函数会接受一个 schemas 参数,用于规则信息的传入;这个类还需要有一个 parse() 方法,接受命令行参数字符串,返回解析结果。
其中的 schemas 就是要传入的规则信息,具体怎么定义还没想好,可以暂缓一下。
那么解析结果怎么定义呢?还是要从使用者的角度来看:当用户拿到 result 这个解析结果之后,就可以向它“询问”某个参数的值了。比如,“询问” p 参数的值,应该得到 8080 这个数字。也就是说,调用 result.get('p') 方法,应该返回 8080。这就是一条清楚的需求验证了,我们需要用测试代码把它固化下来:
expect(result.get('p')).toEqual(8080);
其中的 expect(X).toEqual(Y),是测试框架里面用于验证 X 必须等于 Y 的写法,应该还是容易看懂,这里就不展开了,具体语法,请参见 [2]。
所以,这行代码的意思就是上面说的“调用 result.get('p') 方法,应该返回 8080”。如果 result.get('p') 返回的结果不是 8080,测试就会报错,我们就知道,实现代码有问题,导致这个需求没有被满足。
这一行测试代码,就是我们针对这个需求的“安全网”。这个需求背后的实现代码,在将来的任何时间,任何人,都可以随便重(zhe)构(teng),因为一旦有人把代码改错了,测试会告诉他/她。相反,如果没有测试的保证,改一个字母都得提心吊胆,不敢确定是否会引入 bug,尤其在上线之前,你懂的。
接下来看规则定义。在 Uncle Bob 的示例 [3] 里面,是用字符串来描述规则的,类似这样:
let schemas = "d,p#,l*";
With all due respect,这是什么鬼?是的,是的,这能解释清楚,"d" 没有修饰符,就是一个布尔类型的参数,参数名是 d;"p#" 的修饰符是 #,就是整数类型的参数,参数名是 p;同理,l 是一个字符串参数。可是你想向每个使用你代码的人都去解释一遍吗?或者是等他们每个人(在不同的时间)来问你一遍?
笔者不是不建议,而是强烈反对,使用这种方式表达规则。如果是这样,那使用我们 ArgumentParser 的人,还要再学习一门“语言”,加重了使用者的负担。那么,有没有更直白的方案,让使用者用起来更容易一些呢?
肯定有的。首先想到的是,"d,p#,l*" 这个字符串传进来,我们也是需要做解析的。那么解析的结果是什么样子呢?最直观的方式,应该是每个参数(参数名和参数类型)对应一个对象,所有参数定义就是这个对象的列表或者集合。既然如此,为何不直接让使用者把参数的规则对象传进来呢?就像这样:
let schemas = [
new Schema('d', 'boolean'),
new Schema('p', 'integer'),
new Schema('l', 'string'),
];
嗯,这样看起来清楚一些了。不过用 'boolean'、'integer'、'string' 这类的字符串来表示类型还是不大妥当。为什么?这是用户传进来的,如果用户敲这个单词的时候敲错了呢?比如把 'string' 敲成了 'strong',IDE 是发现不了这类问题的,只有程序运行起来才能发现,很容易出错。
还是回到用户角度,我们说从用户角度考虑,不但要让用户用起来简单,还要让用户不容易用错。能让 IDE 发现问题,是不容易用错的重要方式之一。解决办法就很多了,比如可以定义常量,或者定义枚举,都可以。类似这样:
let schemas = [
new Schema('d', BooleanArgument),
new Schema('p', IntegerArgument),
new Schema('l', StringArgument),
];
其实,如果类型的总数不多,还可以考虑把参数和类组合,少传一个参数,改为使用不同的类:
let schemas = [
new BooleanSchema('d'),
new IntegerSchema('p'),
new StringSchema('l'),
];
嗯,不错,这样用户用起来就更简单了,而且还不容易出错。完了吗?没有,还可以更简单。是的,
时刻考虑如何让你的用户更方便。
这样才能体现你的价值。什么麻烦事都扔给别人了,要你干啥?如果我们引入工厂模式 [4],用户就可以这样用:
let schemas = [
BooleanSchema('d'),
IntegerSchema('p'),
StringSchema('l'),
];
整合一下,就是我们用测试代码,对需求的描述了:
let schemas = [
BooleanSchema('d'),
IntegerSchema('p'),
StringSchema('l'),
];
let parser = new ArgumentParser(schemas);
let commandLine = '-d -p 8080 -l /usr/logs';
let result = parser.parse(commandLine);
expect(result.get('d')).toEqual(true);
expect(result.get('p')).toEqual(8080);
expect(result.get('l')).toEqual('/usr/logs');
拿着这几行测试代码,去跟要使用你代码的人聊聊,看看这是不是他/她想要的,如果是,就可以进入下一步了;如果不是,赶紧改。是的,没错,
在写下第一行实现代码之前,就应该把需求确认了。
设想一下:本来你报了 3 天的工作量,2 天就美滋滋的写完了,心想着明天可以摸一整天的鱼了。结果人家告诉你,需求理解错了,按照“新”需求,你还需要 2 天才能写完。怎么办?估计只有通宵了……所以,
学好 TDD,可以少加班!
是的,我们这个例子比较特殊,用户恰好也是开发人员,我们可以给他们看代码。但是在实际工作中,用户我们是接触不到的,只有产品经理/PO 代表用户。而产品经理/PO 又不懂代码,没法用代码跟他们沟通。还记得前面的 expect(X).toEqual(Y) 不?不给他们看代码,但是你得找他们把这里的 X 和 Y——也就是功能的“输入”和“输出”——沟通清楚。否则你的 X 和 Y 就写不出来,后续步骤也就无法继续。
然后呢?自然是迎娶白富美,走向人生巅峰。哦,哦,歪楼了,其实是,TDD 还有更多让你少加班的“招数”,下面我们接着看。
拆分任务
需求清楚了,接下来该“放我回去写代码”了吧。如果你此刻是这样想的,那么这就是你和高手之间的差距。高手是怎么玩的?
斯诺克
你见过高手打斯诺克(桌球)吗?真正的高手,会通过走位,让自己每一杆球的难度都尽可能的低。是他/她们打不进高难度的球吗?难道打进高难度的球,不是更赏心悦目吗?很可惜(对观众来说),斯诺克选手的首要任务是赢得比赛。要赢得比赛,就要尽可能减少失误,因为你一个失误,被对手(同样是高手)抓住,这局就 gg 了。很显然,即使是顶尖高手,一个高难度的球也会比一个低难度的球,更容易失误。所以他/她们会尽力让每杆球都简单。
一行代码
写代码也是一样的,即便是笔者这个写了二十多年代码的老司机,在没有测试保障的情况下,写 100 行代码,肯定是比写 10 行代码,出 bug 的几率更高;进一步的,写 1 行代码,自然是比写 10 行代码,出 bug 的几率更低。
什么?你是认真的吗?1 行代码能干什么?这里就要提到笔者对 TDD——测试驱动开发的理解了。有测试,有开发,就算测试驱动开发吗?当然不算,尤其是那些后补的测试;那么先写测试,再写实现,就是测试驱动开发了吗?也不一定,要看你的测试是否【驱动】了你的开发。所以关键在驱动。怎么理解这个驱动?
变速器
如果你开过车,或者骑过山地自行车,应该知道这个简单的事实:同样一脚(油门或是脚蹬子)下去,如果你的车当时在 1 档,跑的距离,肯定没有车在 5 档时,跑的距离远。但是 1 档也有它的优点,那就是更有劲,学过中学物理,就知道这是因为 1 档扭矩大。简单粗暴(不严谨)的理解就是:
同样的动力,走的距离越短,驱动力就越大。
再看一行代码
对应到软件开发:
同样的需求,实现它用的代码越少,驱动力就越大。
为什么这么说?每次写的代码尽量少,有哪些好处?
- 代码越少,越不容易写错——代码质量高、改 bug 的时间少
- 代码越少,写起来越轻松——心理压力小
- 代码越少,反馈速度越快——频繁的成就感
其中“改 bug 时间少”这个好处可是大大的。通常情况是这样:不用 TDD,撸码一小时,调试一整天;用了 TDD,两个小时直接搞定,剩下时间嘛,就看其他人有没有 TDD 了:)
所以,笔者看一个人 TDD 做得好不好,就看他/她一次写的实现代码是不是足够少。用行话说就是小步快跑。反过来也有一句行话,就是步子大了会扯到那啥。能少到多少?喂,喂,不写肯定是不现实的了,每次 1 行,是有可能的,我们后面就会演示到。
等等,“我读书少,你别骗我”,你肯定要说了,“哪有那么好的事情,这需求我 1 行搞不定啊”。放心,这需求,换谁来 1 行也搞不定。那怎么办?拆呀。一个大需求,可以拆分出若干小需求/小任务。每一个小任务拆到足够简单,我们实现它用的代码就足够少了。
高手能搞定复杂的问题,不是因为他/她能一把“梭哈”(嗯,天才可以,不在我们讨论范畴)解决整个问题,而是能把复杂问题拆解成一堆简单的问题,然后挨个解决。所以,
确认需求后,不是立刻写代码,而是拆任务。
拆任务
任务拆得大还是小,决定了你是 1 档起步还是 5 档起步。让我们来尝试一下 1 档起步吧。
作为一个负责任的开发人员,不能假装所有的事情都会一帆风顺,所以,除了正常的业务逻辑,你还必须考虑异常情况。这一点千万不要忘了,否则就是把脸伸出去给别人打哦。所以我们的第一个任务清单,长这个样子:
- 处理正常业务逻辑
- 处理异常情况
这也太简单了吧?对呀,
记住,小步前进。
那么“正常业务逻辑”有哪些呢?首先应该想到的,是支持默认值。为什么?控制变量法。我们的解析器接收两个参数(变量),如果有一个参数可以不传(或者为空),我们就可以只针对另外一个参数(单一变量)进行处理。这样可以降低难度,是的,
拆任务的关键,降低实现难度。
而规则信息为空是没有意义的,所以首先应该处理命令行参数为空的情况,这就是参数默认值的需求(还记得这个需求吗?如果忘了,回头再看一眼)。现在的任务清单:
- 处理参数默认值
- 处理非空参数
- 处理异常情况
非空参数,就对应各个不同类型的参数了。有整数、布尔、字符串,如果是你,会首先支持哪种类型的参数解析?想想。3,2,1,公布答案,应该先支持布尔型。为什么?因为布尔型的参数后面不用跟参数值的解析,
难度更低。
接下来支持那种类型?还是有区别的哦。再想想,3,2,1,叮咚,应该先支持字符串类型。为什么?因为你接收的命令行参数就是字符串,所以提取出字符串不需要做类型转换——而整数类型的参数提取完之后还需要转换类型——所以字符串类型的解析,
难度更低。
现在任务清单就变成这样了:
- 处理参数默认值
- 处理布尔型参数
- 处理字符串型参数
- 处理整数型参数
- 处理异常情况
参数默认值的处理,显然也是和参数类型相关的,我们沿用刚才确定的参数类型优先顺序:
- 处理参数默认值
- 处理布尔型参数的默认值
- 处理字符串型参数的默认值
- 处理整数型参数的默认值
- 处理布尔型参数
- 处理字符串型参数
- 处理整数型参数
- 处理异常情况
除了参数类型,还有一个变量维度哦,能想到吗?对了,就是参数个数,有了刚才的铺垫,相信你不会想要首先处理 5 个参数的解析,对吧。对吗?另外,别忘了,还有个附加题,就是对列表型参数的支持。任务列表更新:
- 处理参数默认值
- 处理布尔型参数的默认值
- 处理字符串型参数的默认值
- 处理整数型参数的默认值
- 处理 1 个参数
- 处理布尔型参数
- 处理字符串型参数
- 处理整数型参数
- 处理 2 个参数
- 处理 3 个参数
- 处理异常情况
- 处理列表型参数
任务清单到这个程度,就可以开工了。机智的你一定发现了,多个参数、异常情况,以及列表型参数,这几个任务还可以再拆的。是的,不过没有必要现在拆。目前已经有 6 个小任务,足够我们开发一阵子的了,谁知道这几个小任务做完之后,剩下的任务会不会因为需求变化而被砍掉呢。另一个原因是,随着开发的进行,我们对需求本身可能有更进一步的认识,到时候再做拆解,可以做得更好。这称之为延迟决定,也就是当你做决定所需要的信息还不够充分时,先不着急做决定,等到更多的信息浮现出来,再做决定。所以,
不要过早的拆分过多任务。
所以拆多了不好,那么压根不拆呢?我们简单算笔账:数一下,刚刚拆出来了 10 个任务(只数叶子节点)。对于不拆任务的人来说,直接上手干,就是一次性实现 10 个需求;而对于拆了任务的人来说,一次只需要实现 1 个(很小的)需求。结果嘛,应该不需要多说,大概相当于一口吃 10 勺饭,和一口吃 1 勺饭的区别:)或者说,
需求拆小了就是 1 档起步,没拆就是 10 档起步。
所以呢,如果有人说:“我们的需求太复杂,用不了 TDD”,你就知道了,这个同学不会拆任务。不信让他/她拆出来试试,大部分真实业务需求的复杂度都不如我们做的这道题。就像熊节老师说的,连四则运算都没用全,还好意思说需求复杂。
看完这篇文章,你再去看看那些拿到需求,就开始写 for 循环的人,水平大概是怎么样的,你心里就该有数了。简单复习一下,拿到需求,首先应该干什么?
- 确认需求
- 拆分任务
接下来,终于可以开始写代码了:)
如果你一口气看到这里,建议你可以去休息一下了,继续看下去,效率降低,有可能错过精彩内容:)
环境准备
欢迎回来,开始编码前,我们需要先准备好开发环境。
Node.js
从 https://nodejs.org/en/download/ 下载安装包进行安装;
Yarn
从 https://yarnpkg.com/lang/en/docs/install 下载安装包,并按照页面上的说明进行安装;
基础代码
从 https://github.com/mophy/tdd-starter-js 下载最新代码,并安装依赖包:
git clone https://github.com/mophy/tdd-starter-js.git args
cd args
yarn install
yarn test
如果能看到绿色的 1 passed 字样,就可以了;否则的话,嗯,上网搜一下吧。
开发环境
墙裂推荐使用 WebStorm 作为开发环境,最聪明的 IDE,不解释。
概念复习
在这里只简单复习一下,后面的实践中,都会涉及到,不展开介绍。
开发流程(红,绿,重构)
- 写一个会失败的测试用例,跑一遍(不通过,红色)
- 写刚好能让测试通过的实现,跑一遍(通过,绿色)
- 识别坏味道,重构代码,跑一遍(通过,绿色)
goto 1
三条规则
- 除非是为了使一个失败的测试用例通过,否则不允许编写任何实现代码
- 在一个测试用例中,只允许编写刚好能够导致失败的内容(编译错误也算失败)
- 只允许编写刚好能够使一个失败的测试用例通过的实现代码
上手编码
准备 IDE
开始编码前,还需要把你的 IDE 准备好:
- 请确保你已经完成了前面【环境准备】中的步骤;
- 启动 IDE(本文以 WebStorm 为例),打开工程:【File】->【Open】,选择刚才下载的
args目录,【Open】; - 在 IDE 里打开一个 Terminal(就在你 IDE 窗口的最下方),在 Terminal 中执行
yarn test:watch,测试就在这里跑起来了,一旦有任何一个文件内容有变动,测试就会自动重跑。接着把这个 Terminal 的窗口缩小到大概占整个屏幕的四分之一,确保你编码时能随时看到它的最后几行,就可以了; - 把
test/hello-world.test.js和main/hello-world.js两个占位文件删掉,这时可以看到,Terminal 里面的测试已经自动重跑了,不过因为没有找到测试文件,所以报告的是No tests found...,不用理会,我们马上就会有测试了。
开始编码
啰嗦一句。TDD 这个东西,光靠看,是没有用的,你得动手练。所以,接下来的环节,请你打开 IDE,跟着我们一起练,否则不会有什么实质性的收获的。嗯,确定要练了?往上翻,把环境准备好先:)
立刻就可以写实现代码吗?不行,记住第一条规则,必须先有测试。有测试之前,得先有测试文件。在 test 目录中,新建一个名为 argument-parser.test.js 的文件,这就是我们的测试文件了。在该文件中加入如下内容:
import { ArgumentParser } from '../main/argument-parser';
describe('ArgumentParser', () => {
describe('处理默认参数', () => {
it('处理布尔型参数的默认值', () => {
// todo: start from here
});
});
});
其中 it 包裹的就是一个个具体的测试用例,describe 暂时理解为用于组织测试用例的文件夹就好了。可以看到,这第一个测试用例,就是我们前面拆分出来的第一个任务。
这时你会发现测试无法通过(变红了),因为 argument-parser 文件不存在。让我们来修正这个问题,把光标放到这个文件名的地方(字符串里面),敲 Alt + Enter,选择【Create file ‘argument-parser.js’ with class ‘ArgumentParser’】,回车。此时 IDE 会自动帮你生成这个文件,并且可以看到对应的类也创建好了。Ctrl + S/Cmd + S 保存这个文件,测试自动重跑,通过了(变绿了)。
接下来引入一行测试代码:
it('处理布尔型参数的默认值', () => {
let schemas = [BooleanSchema('d')];
});
保存,可以看到,又变红了,因为 BooleanSchema 未定义。修正他,把光标停留在这个单词上,Alt + Enter,选择【Create Function ‘BooleanSchema’】,然后选择【global】,函数就自动创建好了:
function BooleanSchema(d) {
return undefined;
}
保存,测试通过(变绿)。等等,是的,你一定会问的,“这代码啥用也没有啊”。目前看起来是的,不过这些代码会逐渐演变为有用的代码的。我们是为了让每一步都尽可能简单(步子小),故意引入了假实现——准确的说,是暂缓实现。毕竟他的结果目前还没有真正用到,所以可以这么干。事实上,这是 TDD 的常见手法,我们以后会经常这么干。
记住,让步子变小,是 TDD 的精髓。
测试通过之后,就应该考虑重构了。很显然,BooleanSchema 的定义是属于实现代码,不应该出现在测试文件里面,我们把它移走。光标停留在这个函数的定义处,快捷键 F6,出现【Move Module Members】窗口,把【To】的最后部分——test/argument-parser.test.js,改为 main/schema.js,点【Refactor】按钮,提示创建文件,选【Yes】,文件就创建好了。保存,可以看到测试仍然是绿的。
到现在,你已经体验了一次“红,绿,重构”的 TDD 经典循环了。后面我们会反复体验这个循环。
继续完善我们的测试代码:
it('处理布尔型参数的默认值', () => {
let schemas = [BooleanSchema('d')];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get('d')).toEqual(false);
}
好,又变红了,说 parse() 方法未定义,我们来让它变绿。在 ArgumentParser 类中加入 parse() 方法:
parse(commandLine) {
return { get: () => false };
}
保存,变绿,搞定。“你是在玩我吗”?是的,不,不是。TDD 常用手法:假实现。要尽快让测试通过,一旦测试通过了,就可以使劲重构。然后我们再在重构步骤中,把真实现加上。
来重构吧。首先需要创建一个 Arguments 类用于存放解析结果:
class Arguments {
get() {
return false;
}
}
然后替换 ArgumentParser.parer() 方法的实现:
parse(commandLine) {
return new Arguments();
}
保存一下,测试通过,继续重构。Arguments 类不应该跟 ArgumentParser 类放在一起,把他移走。光标停留在 Arguments 类的定义处,敲 F6,将【To】内容的末尾改为 main/arguments.js,点【Refactor】,点【Yes】,新文件建好了。如此,便把 Arguments 类移动到了新建的 main/arguments.js 文件里面,保存,测试仍然通过。
停下来看看,现在第一个任务的测试用例是完整的,通过假实现也能让测试通过。那么我们现在是不是可以开始做第二个任务了呢?这个要根据具体情况进行评估。先看现状,对于第二个任务(处理字符串型参数的默认值),我们是否能用很少的代码让他通过呢?考虑到目前全部是假实现,所以很显然不能。那么我们需要继续重构,加入真实现。
什么?假实现变真实现也能叫重构?重构不是不能改变代码的行为吗?是的,不过这个行为前面还有个限定词:“external” [5],外部行为,也可以理解为可观测的行为。目前我们对实现代码的观测仅限于已有的测试用例,也就是说,用目前的测试用例来“观测”实现代码,行为是没有改变的。应该这样来理解重构。相反,那些引入 bug 的修改,则不能算是重构,因为引入 bug 明显改变了可观测的行为。简单的说,没有测试保证,你就很可能不是在重构,而是在……你懂的。
接着重构。真实现肯定要使用传入的规则定义,所以我们需要把传入的 schemas 存起来,为 ArgumentParser 加入一个构造函数:
constructor(schemas) {
this.schemas = schemas;
}
保存,仍然是绿的,没问题,可以继续。接下来怎么使用这个 schemas 呢?从需求的角度可以看出,一个规则定义,肯定对应一个解析出来的参数,也就是有个一一对应的关系。规则(定义)和参数(结果),都还没有对应的类,我们就从这里开始。在 schema.js 文件中加入规则类的定义,他需要由标志和类型两个属性:
class Schema {
constructor(flag, type) {
this.flag = flag;
this.type = type;
}
}
保存,还是绿的,继续。修改 BooleanSchema 函数的实现:
export function BooleanSchema(flag) {
return new Schema(flag, 'boolean');
}
保存,仍然是绿的。且慢,“你不是说不要用字符串做类型参数吗”?是的,不过,这个说法的主语是用户,不要让用户这样去用。而目前的代码是在我们的实现内部,不会给用户带来困扰,而且我们还有测试保证。“所以我们就要降低要求了”?不会的,我们先把精力放在核心业务上,后面我们会“收拾”它的。
接下来在 argument-parser.js 文件中增加一个参数类的定义,它需要标志和值这两个属性:
class Argument {
constructor(flag, value) {
this.flag = flag;
this.value = value;
}
}
保存,绿的。对应关系的两端——Schema 类和 Argument 类——都有了,接下来该使用它们了。既然是一一对应,那么 Schema 的列表也应该对应 Argument 的列表,而我们的 Argument 的载体——Arguments 并不是一个列表。不怕,我们可以让它接收一个列表来进行构造就好了。调整 parse() 方法的实现:
parse(commandLine) {
let args = this.schemas.map(schema => undefined);
return new Arguments(args);
}
保存,绿的,继续重构。从那个 undefined 可以看出,这里又用了假实现,是的,记住,小步前进,现在还没到实现它的时候。机制如你,又会问了,“怎么区分哪些是需要现在实现的,哪些是要放在后面实现的呢”?这个问题非常好,其实你仔细思考一下,this.schemas.map() 和 schema => undefined 之间其实是有一个层级关系的,前者是上级,后者是下级。所以,只要记住先写上级就好。就好像写文章的时候,先列大纲,就先写一级标题:第一章、第二章、第三章,然后再写第一章里面的二级标题:第一节、第二节、第三节。写代码的时候,也是这样。
接下来为 Arguments 创建构造函数,毕竟数据都已经穿进去了,至少得存起来。将光标停留在 (args) 里面,Alt + Enter,选择【Create constructor in class ‘Arguments’】,构造函数就创建出来了,填入实现代码:
constructor(items) {
this.items = items;
}
保存,还是绿的。继续完善 ArgumentParser.parse(),看看里面的 schema => undefined 实际上是要干什么呢?是要把一个规则定义转换为对应的默认值,所以我们抽取一个方法:选中 undefined,敲 Ctrl + Alt + M/Cmd + Alt + M(抽取方法的快捷键),选择【class ArgumentParser】,将方法命名为 getDefaultValue,传入 schema 参数,现在 ArgumentParser 大概是这个样子:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
return new Arguments(args);
}
getDefaultValue(schema) {
return undefined;
}
保存,绿的。接着实现 getDefaultValue() 方法,根据 schema 的类型,创建 Argument 对象:
getDefaultValue(schema) {
if (schema.type === 'boolean')
return new Argument(schema.flag, false);
return undefined;
}
保存,绿的。现在,既然参数都已经传进 Arguments 类了,需要把它用起来,调整 Arguments.get() 方法的实现,根据标志找到对应的参数,并返回参数的值:
get(flag) {
return this.items.find(item => item.flag === flag).value;
}
保存,绿的。看看代码,还有什么需要重构的吗?很明显,Argument 类不应该放在 argument-parser.js 文件里面,光标放在这个类里面,F6,把它移动到新建的 main/argument.js 文件里面。保存,绿的。
目前的代码清单如下,test/argument-parser.test.js:
import { ArgumentParser } from '../main/argument-parser';
import { BooleanSchema } from '../main/schema';
describe('ArgumentParser', () => {
describe('处理默认参数', () => {
it('处理布尔型参数的默认值', () => {
let schemas = [BooleanSchema('d')];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get('d')).toEqual(false);
});
});
});
main/argument-parser.js:
import { Arguments } from './arguments';
import { Argument } from './argument';
export class ArgumentParser {
constructor(schemas) {
this.schemas = schemas;
}
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
return new Arguments(args);
}
getDefaultValue(schema) {
if (schema.type === 'boolean')
return new Argument(schema.flag, false);
return undefined;
}
}
main/schema.js:
class Schema {
constructor(flag, type) {
this.flag = flag;
this.type = type;
}
}
export function BooleanSchema(flag) {
return new Schema(flag, 'boolean');
}
main/argument.js:
export class Argument {
constructor(flag, value) {
this.flag = flag;
this.value = value;
}
}
main/arguments.js:
export class Arguments {
constructor(items) {
this.items = items;
}
get(flag) {
return this.items.find(item => item.flag === flag).value;
}
}
到这里,第一个任务算是做完了,庆祝一下,休息休息。
第二个小任务
第二个任务,处理字符串型参数的默认值。老套路,先写一个失败的测试:
it('处理字符串型参数的默认值', () => {
let schemas = [StringSchema('l')];
});
是的,你没看错,只写了一行。为什么不把剩下的几行写完?这就要回头看看 TDD 三条规则里面的第二条:“只允许编写刚好能够导致失败的内容”。如果剩下几行也写了,那么就有 StringSchema 未实现,以及 parse() 未处理字符串逻辑,这两个导致失败的内容了。进一步的,为了使测试通过,需要更多的实现代码,提高了复杂度。所以,这第二条规则的主要目的,就是要使失败的测试,能够以最简单的方式、最快的速度通过。这不仅降低了出错的可能性,而且能让我们尽可能的保留在测试通过(变绿)的状态,也就降低了心里负担。毕竟,写了半天,却不知道写得有没有问题,是一个很糟糕的体验。
好,我们来让它变绿。先在使用 StringSchema() 的位置敲 Alt + Enter,创建函数。保存,测试通过了。
function StringSchema(flag) {
return undefined;
}
开始重构,首先 F6,将函数移动到 main/schema.js 文件里面,然后为 StringSchema() 加入实现:
export function StringSchema(flag) {
return new Schema(flag, 'string');
}
保存,还是绿的,嗯,我们的修改没有破坏测试。
继续完善测试,又让它变红:
it('处理字符串型参数的默认值', () => {
let schemas = [StringSchema('l')];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get('l')).toEqual('');
});
为 ArgumentParser.getDefaultValue() 加入实现代码,让测试变绿:
getDefaultValue(schema) {
if (schema.type === 'boolean')
return new Argument(schema.flag, false);
if (schema.type === 'string')
return new Argument(schema.flag, '');
return undefined;
}
保存,绿了。恭喜,第二个任务完成了!先别急,看看这个代码有没有需要重构的呢?嗯,getDefaultValue() 里面的两个 if 有点坏味道,不过现在还没有必要重构它。为什么?在这里给大家推荐一个原则:“不要被同一颗子弹击中两次”。对应到这份代码,一个 if 语句是没有问题的;第二个 if 和第一个 if 有很强的相关性,这就是击中我们的第一颗子弹了。如果需求永远定格在这里,那么这个不是什么大问题。相反,如果需求增加,导致我们需要增加第三个相关的 if 语句,那么这就是第二颗子弹了,届时,我们将需要重构以解决这个问题。
好,开始第三个任务。仍然是先写一个变红的测试:
it('处理整数型参数的默认值', () => {
let schemas = [IntegerSchema('p')];
});
实现 IntegerSchema() 让它变绿:
function IntegerSchema(flag) {
return undefined;
}
重构,将 IntegerSchema() 移动到 main/schema.js 文件,保存,绿的。继续重构,为 IntegerSchema() 加入实现:
export function IntegerSchema(flag) {
return new Schema(flag, 'integer');
}
保存,还是绿的。继续完善用例,让测试变红:
it('处理整数型参数的默认值', () => {
let schemas = [IntegerSchema('p')];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get('p')).toEqual(0);
});
保存,红了。为 ArgumentParser.getDefaultValue() 加入实现代码:
getDefaultValue(schema) {
if (schema.type === 'boolean')
return new Argument(schema.flag, false);
if (schema.type === 'string')
return new Argument(schema.flag, '');
if (schema.type === 'integer')
return new Argument(schema.flag, 0);
return undefined;
}
保存,绿了。好耶,第三个需求完成!哈哈,别急,好戏才刚刚开始。继续下一个任务之前,我们需要看看有需要可以重构的,记得吧,红,绿,重构。首当其冲的就是上面这个 getDefaultValue(),为什么呢?我们慢慢来看。
在学会写好代码之前,你得知道什么样的代码是不好的。获取这个知识最直接的途径,就是《重构》这本书。如果你时间紧迫——嗯,如果你还不会 TDD,那么通常时间都很紧迫,毕竟写 bug 和改 bug 都很花时间——那么可以只看其中的【代码的坏味道】这一章。豆瓣上该书的第一条评论(截止本文撰写时止)是:“程序员保命神书!”,嗯,程序员必读。
- 首先,如果把该方法中的三个字符串全部抠掉,然后把传给
Argument构造函数的第二个参数也全部抠掉,那么剩下的三个if语句是完全一样的。也就是说,这是“重复代码”的味道; - 其次,虽然这里看起来是三个
if,但其实它们干的是switch语句的事情,也就是“switch惊悚现身”的味道; - 第三,这个方法位于
ArgumentParser类。也就是说,不但解析规则的变化会导致该类发生变化,而且默认值规则变化,也会导致该类发生变化,这就是“发散式变化”的味道; - 第四,新增任意类型,不但会导致
main/schema.js文件发生变化,还会导致ArgumentParser类发生,这就是“霰弹式修改”的味道。
我滴个乖乖,短短几行代码,居然有那么多的问题。在继续之前,我们来直观感受一下这里的重复代码。我们把 if 条件里面的三个字符串全部替换成 'xxx',然后把 new Argument 的第二个参数全部替换成 yyy,再把 return 前面的换行去掉,结果就是这样:
if (schema.type === 'xxx') return new Argument(schema.flag, yyy);
if (schema.type === 'xxx') return new Argument(schema.flag, yyy);
if (schema.type === 'xxx') return new Argument(schema.flag, yyy);
一模一样吧。要学会以这种方式考察重复代码。好了,这段代码问题虽多,不过没关系,我们来慢慢重构它。对于 switch 语句,《重构》里面有很明确的解决方案,就是多态。简单的说,就是引入一个父类,然后有几个分支,就引入几个子类。
那么这个父类,是新建一个呢,还是“挂靠”在某个已有的类上面呢?要确定一段代码应该放在什么地方,关键是要分析它的职责,也就是它要解决什么业务问题。这段代码的职责是,根据参数类型,确定参数默认值。这和规则定义有很大的关系,所以,可以放在规则定义的类上面。不过,既然提到参数类型,那么为什么不直接引入参数类型的类定义呢?这样做更加纯粹一些,更加符合单一职责原则。
也就是说,我们需要一个参数类型类:ArgumentType,它有一个获取默认值的方法:default()。然后三个参数类型各对应一个相应的子类。我们先新建一个 main/argument-type.js 文件,并为其加入 ArgumentType 类的定义:
export class ArgumentType {}
保存,还是绿的。加入布尔型参数类型的定义:
export class BooleanArgumentType extends ArgumentType {
static default() {
return false;
}
}
保存,绿的。然后就可以修改 ArgumentParser.getDefaultValue() 里面对应的那行代码:
if (schema.type === 'boolean')
return new Argument(schema.flag, BooleanArgumentType.default());
保存,绿的。继续修改 ArgumentParser.getDefaultValue(),但是先不要保存,否则会变红:
if (schema.type === BooleanArgumentType)
return new Argument(schema.flag, BooleanArgumentType.default());
然后修改 BooleanSchema() 的实现:
return new Schema(flag, BooleanArgumentType);
现在保存,还是绿的。用同样的办法分别(按步骤)引入 StringArgumentType 和 IntegerArgumentType。于是 main/argument.js 文件就变成了这样:
export class ArgumentType {
static default() {
return undefined;
}
}
export class BooleanArgumentType extends ArgumentType {
static default() {
return false;
}
}
export class StringArgumentType extends ArgumentType {
static default() {
return '';
}
}
export class IntegerArgumentType extends ArgumentType {
static default() {
return 0;
}
}
而 main/schema.js 文件则变成了这样:
import { BooleanArgumentType, IntegerArgumentType, StringArgumentType } from './argument-type';
class Schema {
constructor(flag, type) {
this.flag = flag;
this.type = type;
}
}
export function BooleanSchema(flag) {
return new Schema(flag, BooleanArgumentType);
}
export function StringSchema(flag) {
return new Schema(flag, StringArgumentType);
}
export function IntegerSchema(flag) {
return new Schema(flag, IntegerArgumentType);
}
请注意,该文件里面使用字符串作为类型的代码也被干掉了,算是履行了前面的承诺吧:)接着是 ArgumentParser.getDefaultValue():
getDefaultValue(schema) {
if (schema.type === BooleanArgumentType)
return new Argument(schema.flag, BooleanArgumentType.default());
if (schema.type === StringArgumentType)
return new Argument(schema.flag, StringArgumentType.default());
if (schema.type === IntegerArgumentType)
return new Argument(schema.flag, IntegerArgumentType.default());
return undefined;
}
测试仍然是绿的。接下来,就是见证奇迹的时刻,继续修改 getDefaultValue():
getDefaultValue(schema) {
return schema.type.default();
}
保存,哈哈,红了!嗯,改出错了。怎么排查?太简单了,我们刚才就改了一个方法,所以引入的问题肯定就在这个方法里面呗,跑不出这个小框框。仔细看看,哦,代码删多了,再来:
getDefaultValue(schema) {
return new Argument(schema.flag, schema.type.default());
}
好,这下绿了。看看,代码大幅度简化了吧,前面提到的各种坏味道也没有了吧。所以,记住了,下次遇到 switch 语句,就这么重构。不过,前提是你得有测试保证,否则……否则别把我的名字说出去 :-p
重构完了吗?可以开始下一个任务了吗?不,还没有。有这样一种论调,说“我们业务变动太频繁,用不了 TDD,否则测试代码的维护量太大了”。看到这种论调,你就知道,他/她们要么不会做重构,要么,没有对测试代码做重构。哦?测试代码也要重构?是的,除非你不打算继续维护它们了。为了今后维护的方便(快捷、不容易出错),我们要重构生产代码。同样的理由,我们也应该重构测试代码。简单的说,
测试代码和生产代码同等重要。
难道不是吗?有还是没有测试代码,是区分你是在写功能,还是在写 bug 的重要标志。如果你不希望别人对你说:“你是我司请来写 bug 的吗?”,你还敢说它们不重要吗?
好,我们来看看测试代码有没有什么可以重构的地方。很显然,是有的。三个 it 里面有大量的重复代码,应该把它们提取出一个公共的方法来。如何提取?把三个方法里面不同的地方抠出来,剩下的,就是共同的东西了,也就是——大家来找茬。可以看到,有三处不同,首先是参数类型,其次是参数标志,最后是默认值。于是,这三个就是我们提取出来的方法的参数。
还是一步一步来。首先选中第一个 it 的大括号里面所有的内容(不包括大括号本身),敲 Ctrl + Alt + M/Cmd + Alt + M,提取方法,将新方法命名为 testDefaultValue,于是第一个 it 变成这样:
it('处理布尔型参数的默认值', () => {
testDefaultValue();
});
文件顶端多出来一个方法:
function testDefaultValue() {
let schemas = [BooleanSchema('d')];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get('d')).toEqual(false);
}
保存,绿的。选中 BooleanSchema 这几个字(注意不要选到括号及括号后面的内容了),敲 Ctrl + Alt + P/Cmd + Alt + P,抽取参数,命名为 schemaType。保存,绿的。testDefaultValue() 方法的参数签名变为了:
function testDefaultValue(schemaType = BooleanSchema)
把这个参数默认值的声明删掉,改为从 it 里面调用时传入。于是这个方法的签名就变成了:
function testDefaultValue(schemaType)
而在第一个 it 里面对它的调用则变为了:
testDefaultValue(BooleanSchema);
保存,还是绿的。开始提取标志参数。选中 'd'(包括单引号),敲 Ctrl + Alt + P/Cmd + Alt + P,抽取参数,在弹窗中选择【Replace all 2 occurences】,回车,命名为 flag。保存,绿的。同样把参数签名中的默认值删掉,改为调用方传入。于是参数签名变为:
function testDefaultValue(schemaType, flag)
第一个 it 里面则变为:
testDefaultValue(BooleanSchema, 'd');
保存,绿的。继续提取默认值参数。选中 false,抽取参数,命名为 defaultValue,保存,绿的。这次 IDE 自动帮我们做好了传参,我们只需要把参数前面中的默认值删掉即可。于是我们提取的公共方法就变成了这个样子:
function testDefaultValue(schemaType, flag, defaultValue) {
let schemas = [schemaType(flag)];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get(flag)).toEqual(defaultValue);
}
第一个 it 则是这个样子:
it('处理布尔型参数的默认值', () => {
testDefaultValue(BooleanSchema, 'd', false);
});
保存,还是绿的。接下来就简单了,把第二个 it 里面的内容替换为:
it('处理字符串型参数的默认值', () => {
testDefaultValue(StringSchema, 'l', '');
});
保存,仍然是绿的。接着处理第三个 it:
it('处理整数型参数的默认值', () => {
testDefaultValue(IntegerSchema, 'p', 0);
});
保存,绿的。最终的测试文件就是这个样子了:
import { ArgumentParser } from '../main/argument-parser';
import { BooleanSchema, IntegerSchema, StringSchema } from '../main/schema';
function testDefaultValue(schemaType, flag, defaultValue) {
let schemas = [schemaType(flag)];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get(flag)).toEqual(defaultValue);
}
describe('ArgumentParser', () => {
describe('处理默认参数', () => {
it('处理布尔型参数的默认值', () => {
testDefaultValue(BooleanSchema, 'd', false);
});
it('处理字符串型参数的默认值', () => {
testDefaultValue(StringSchema, 'l', '');
});
it('处理整数型参数的默认值', () => {
testDefaultValue(IntegerSchema, 'p', 0);
});
});
});
看,测试代码也可以很简洁的吧。好了,第一个大任务完成了,又到了该休息的时间了。
第二个大任务
欢迎回来。开始第二个大任务,还是先写测试。为了明确表明大任务和小任务之间的层级关系,测试代码也是应该要组织一下的。大任务本身用 describe 描述(还记得前面说的文件夹的概念吗?),在跟 describe('处理默认参数', ...); 平级的地方加入如下定义,从这个任务拆出来的小任务相关的测试,就放在这个结构里面:
describe('处理 1 个参数', () => {
});
保存,绿的。开始处理这个大任务下面的第一个小任务:“处理布尔型参数”。首先要理解这个需求,对于布尔型参数,命令行里面传了,最后就能 get 出 true;命令行里面没传,最后就只能 get 出 false。后面这种情况,就是默认值的情况,我们已经在前面处理了,所以,现在我们只需要处理前一种情况即可。那么什么叫“传了这个参数”?假设对应的标志是 d,那么就是命令行参数里面有 "-d" 的字样。于是,我们的测试就可以这么写:
it('处理布尔型参数', () => {
let schemas = [BooleanSchema('d')];
let parser = new ArgumentParser(schemas);
let commandLine = '-d';
let result = parser.parse(commandLine);
expect(result.get('d')).toEqual(true);
});
能看明白吧,跟对应的默认值相关测试代码,只有两处不同:一个是命令行 commandLine 里面有传入 "-d";另一个就是最终结果的验证,应该是 true。
保存,红了。不怕,这正是我们期待的结果,接下来的关键是尽快让它变绿。什么方法最快?哈,自然是假实现。你又要问了,我们前面为了让测试变绿,也并不是每次都用的假实现,也有用真实现的,怎么选择呢?很简单,如果真实现能很容易让测试变绿,就用真实现,反之,就先用假实现。一个字,就是要快。
那么这个假实现怎么写呢?无论什么实现,我们先从业务逻辑来看。一个参数的值,如果没传,就用默认值;如果传了,就用实际传入的值。这个可以理解为用实际传入的值(如果有),去替换默认值。也就是说,我们只要在默认值生成之后,搞点“小动作”,然后再返回,就可以了。好办,修改 ArgumentParser.parse() 方法的实现,只需要加一行就搞定了嘛:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
args[0].value = true;
return new Arguments(args);
}
哈哈,这也太假了点吧,没事,能通过就好,后面还有重构呢。保存,恭喜,还是红的。哦,新的这个测试是通过了,不过之前的三个测试全部失败了。拜托,不能这么喜新厌旧啊,让新测试通过的同时,不能破坏已有测试啊,否则就是在写 bug 了哦。还好,我们前面有三个可靠的测试,帮助我们及时发现了这个问题。
赶紧改,不能破坏已有测试,就是说我们不能无差别的这么干。那么首先就要区分出不同的情况,然后才能予以区别对待。这个“不同情况”在哪里?给你三秒钟时间思考:3、2、1,是的,就在 commandLine 这里。还记得吧,前面三个测试是用于测试参数默认值,也就是命令行参数 commandLine 是传的空字符串;而新的情况下,这个参数是有内容的,这就可以区分开了。只需要把方法中的第二行改成这样:
if (commandLine) args[0].value = true;
一如既往的假,不过没关系,测试通过了。现在,我们可以在测试的保驾护航下,放心大胆的重构我们的代码了。别激动,要不要重构还不一定呢。那到底怎么抉择要不要做重构呢?前面是有提到的,不过没有明确的总结出来,我们在这里列一下:
- 代码里面有坏味道
- 下一个任务不好做
- 任何你看不顺眼的地方
回到我们这里的情况,貌似 if (commandLine) 这个条件有些太泛化了,不利于我们继续做下一个任务。考虑到下一个任务中,会有不一样的参数标志,我们可以把对参数标志的判断放在这里。继续修改第二行:
if (commandLine === '-d') args[0].value = true;
保存,测试仍然是绿的。接下来就可以开始下一个小任务了:“处理字符串型参数”。根据需求,可以很容易的写出一个失败的测试,记得要给字符串参数传数据:
it('处理字符串型参数', () => {
let schemas = [StringSchema('l')];
let parser = new ArgumentParser(schemas);
let commandLine = '-l /usr/logs';
let result = parser.parse(commandLine);
expect(result.get('l')).toEqual('/usr/logs');
});
保存,果不其然变红了。快,快,快,尽快让它变绿。在 ArgumentParser.parse() 里面加一行就可以搞定:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine === '-d') args[0].value = true;
if (commandLine.startsWith('-l')) args[0].value = commandLine.substring(3);
return new Arguments(args);
}
保存,绿了。新加的这行,简单解释一下:如果命令行 commandLine 是以 "-l" 这个字符串开头,那么我们就取命令行的后半部分(跳过前三个字符)作为参数的值。现在需要重构吗?从怀味道的角度,两个 if 只能算一颗子弹,还好;下一个任务应该也只需要加一行而已。也就是说,暂时还不需要重构。不过,第二个 if 这行太长了,看着不爽,所以,我们还是小小的重构一下吧:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let [flag, value] = commandLine.split(' ');
if (flag === '-d') args[0].value = true;
if (flag === '-l') args[0].value = value;
return new Arguments(args);
}
嗯,这样看起来清爽些了,保存,还是绿的。
下一个任务,“处理整数型参数”。套路应该都清楚了,先是一个失败的测试:
it('处理整数型参数', () => {
let schemas = [IntegerSchema('p')];
let parser = new ArgumentParser(schemas);
let commandLine = '-p 8080';
let result = parser.parse(commandLine);
expect(result.get('p')).toEqual(8080);
});
保存,变红,没毛病。注意最后一行,验证的这个数据是数值型的 8080,而非字符串 "8080"。因为命令行穿进去的是字符串,所以这里在实现的时候需要记得做类型转换。让它变绿也很简单,仍然只需要在 ArgumentParser.parse() 中加入一行代码即可:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let [flag, value] = commandLine.split(' ');
if (flag === '-d') args[0].value = true;
if (flag === '-l') args[0].value = value;
if (flag === '-p') args[0].value = parseInt(value, 10);
return new Arguments(args);
}
保存,变绿了。如果从通过所有测试的角度来看,我们已经完成了第二个大任务。不过,在开始下一个任务之前,还有很多需要重构的地方在等着我们。别忘了,我们的 parse() 里面还都只是假实现呢,就从这里开始吧。
将目光聚焦在三个并排的 if 语句上。从需求角度,审视这三行代码,直接根据命令行中的参数标志,来决定参数值的处理方式,肯定是不对的。这是硬编码的参数标志,一旦用户定义了别的什么标志,这段代码就挂了。那么正确的方式应该是如何做呢?应该是根据参数标志,找到对应的规则,再根据规则中的类型,进行相应的处理。
方向知道了,该从哪里入手呢?还记得我们前面处理过三个并排 if 语句的情况吗?是的,同样的方法。从第一个 if 里面的判断条件开始。在那之前,先做个小调整,把标志前面的 "-" 去掉。为什么要去掉?因为我们要用这个标志去规则里面去做查找嘛,而规则里面存的是没有前面的 "-" 的,所以,去掉之后可以方便我们做查找:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let [flag, value] = commandLine.substring(1).split(' ');
if (flag === 'd') args[0].value = true;
if (flag === 'l') args[0].value = value;
if (flag === 'p') args[0].value = parseInt(value, 10);
return new Arguments(args);
}
保存,绿的。接下来就可以把对应的规则 schema 找出来,并替换第一个 if 里面的条件:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let [flag, value] = commandLine.substring(1).split(' ');
let schema = this.schemas.find(s => s.flag === flag);
if (schema.type === BooleanArgumentType) args[0].value = true;
if (flag === 'l') args[0].value = value;
if (flag === 'p') args[0].value = parseInt(value, 10);
return new Arguments(args);
}
保存,红了。说 Cannot read property 'type' of undefined,嗯,因为 schema 可能是空。为什么呢?因为前三个测试就没传 commandLine,所以拆出来的 flag 就是空的,也就不可能通过这个 flag 去找到对应的 schema。解决方案也很简单,判断一下,如果没传 commandLine,就不用做这些判断了:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let [flag, value] = commandLine.substring(1).split(' ');
let schema = this.schemas.find(s => s.flag === flag);
if (schema.type === BooleanArgumentType) args[0].value = true;
if (flag === 'l') args[0].value = value;
if (flag === 'p') args[0].value = parseInt(value, 10);
}
return new Arguments(args);
}
保存,绿了。然后呢?好像不是很明确,没关系,那我们继续替换下一个 if 语句的条件:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let [flag, value] = commandLine.substring(1).split(' ');
let schema = this.schemas.find(s => s.flag === flag);
if (schema.type === BooleanArgumentType) args[0].value = true;
if (schema.type === StringArgumentType) args[0].value = value;
if (flag === 'p') args[0].value = parseInt(value, 10);
}
return new Arguments(args);
}
保存,还是绿的。然后呢?还不是很清楚。那就继续替换下一个 if 的条件:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let [flag, value] = commandLine.substring(1).split(' ');
let schema = this.schemas.find(s => s.flag === flag);
if (schema.type === BooleanArgumentType) args[0].value = true;
if (schema.type === StringArgumentType) args[0].value = value;
if (schema.type === IntegerArgumentType) args[0].value = parseInt(value, 10);
}
return new Arguments(args);
}
保存,依然是绿的。接下来呢?这下好像有点头绪,因为后面的 parseInt 是做数据格式转换的,这个逻辑应该是跟参数类型直接相关的,不同的参数类型,肯定会有各自不同的数据类型转换逻辑。因此我们可以把这个代码移动到对应的数据类型里面。选中 parseInt(value, 10),敲 Ctrl + Alt + M/Cmd + Alt + M,抽取方法,命名为 extract,这行代码就变成了:
if (schema.type === IntegerArgumentType) args[0].value = convert(value);
同时在文件顶端出现了一个新的函数:
function convert(value) {
return parseInt(value, 10);
}
保存,绿的。接着把这个函数实现真个剪切下来(Ctrl + X/Cmd + X),粘贴(Ctrl + V/Cmd + V)到 main/argument-type.js 文件的 IntegerArgumentType 类里面,并调整函数声明:
export class IntegerArgumentType extends ArgumentType {
static default() {
return 0;
}
static convert(value) {
return parseInt(value, 10);
}
}
接着调整刚才那一行调用代码:
if (schema.type === IntegerArgumentType) args[0].value = schema.type.convert(value);
保存,还是绿的。这就是对第三个 if 语句的修改。我们再回过头来审视一下第二个 if,末尾的 args[0].value = value 其实也是在做类型转换,不过这个转换的动作是一个“原封不动”的转换。但无论是原封不动,还是 xjb 动,和 IntegerArgumentType.convert() 一样,这个都是数据参数类型自身的逻辑。所以,类似的,我们也把这个“转换操作”移动到 StringArgumentType.convert() 里面。首先选中末尾这个 value,抽取函数,命名为 convert,于是这行 if 就变成了:
if (schema.type === StringArgumentType) args[0].value = convert(value);
抽取出来的函数:
function convert(value) {
return value;
}
保存,绿的。是的,这个函数看起来像个复读机,别人说啥它说啥。不过没事,你要相信,他在逻辑上是合理的,就行了。尤其是把它移动到它应该在的位置之后。调用代码就变成了:
if (schema.type === StringArgumentType) args[0].value = schema.type.convert(value);
而 StringArgumentType 则变成了:
export class StringArgumentType extends ArgumentType {
static default() {
return '';
}
static convert(value) {
return value;
}
}
保存,绿的。同样的逻辑,我们处理第一个 if 语句:
if (schema.type === BooleanArgumentType) args[0].value = schema.type.convert(value);
新的 BooleanArgumentType 类:
export class BooleanArgumentType extends ArgumentType {
static default() {
return false;
}
static convert() {
return true;
}
}
保存,绿的。现在的 ArgumentParser.parse() 长这个样子:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let [flag, value] = commandLine.substring(1).split(' ');
let schema = this.schemas.find(s => s.flag === flag);
if (schema.type === BooleanArgumentType) args[0].value = schema.type.convert(value);
if (schema.type === StringArgumentType) args[0].value = schema.type.convert(value);
if (schema.type === IntegerArgumentType) args[0].value = schema.type.convert(value);
}
return new Arguments(args);
}
三个 if 的判断条件不同,但是分支里面的处理是完全一样的。也就是说,无论出现什么情况,都干同一件事情。既然如此,那么就没有必要再去做任何判断了。于是我们可以把三个 if 一起干掉了:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let [flag, value] = commandLine.substring(1).split(' ');
let schema = this.schemas.find(s => s.flag === flag);
args[0].value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,还是绿的。如何,没有并排 if 的代码清爽多了吧。
那么这部分代码重构做完了吗?就这样看,好像没有太大的感觉。没关系,针对代码味道的重构可以先放一放。我们考虑一下后面的任务是否好做。由于接下来我们要做两个参数的解析,而在目前的实现里,对 commandLine 的拆分,和对 args 值的修改,都是最笨的实现,无法满足两个参数的要求。那我们就从这两个地方开始。
首先是 commandLine 的拆分。目前的拆分方式肯定是有问题的,这是当时为了让测试通过,随便写的。那么,不随便,应该怎么写?还是要回到业务逻辑。对于我们的解析器来说,是要“吃进” commandLine,然后“拉出”……算了,好像不太雅观,再“吐出” Argument。不过它不会一次“吃”整个 commandLine 字符串的(会消化不良),而是一次只“吃”一段。比如对于 -l /usr/logs 这个 commandLine,它会先吃 -l,然后根据 l 找到对应的 schema 以确定数据类型;接着“吃”进 /usr/logs,作为对应的值。既然解析器是一段一段的“吃”,为了方便它,那么我们可以先把 commandLine 拆成一段一段的。再加上已经“吃”过的,不需要再“吃”一遍,也就是说,“吃”一段,少一段。就像这样:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let tokens = commandLine.split(' ');
let flag = tokens.shift().substring(1);
let value = tokens.shift();
let schema = this.schemas.find(s => s.flag === flag);
args[0].value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,绿的。在继续处理 tokens 之前,需要先把 args 值的修改处理了。否则,“吃”再多的 token,也没法赋给对应的 arg。处理也很简单,需要通过 flag 找到对应的 arg 参数,然后为其赋值:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
if (commandLine) {
let tokens = commandLine.split(' ');
let flag = tokens.shift().substring(1);
let value = tokens.shift();
let schema = this.schemas.find(s => s.flag === flag);
let arg = args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,还是绿的。还有一个地方可以改进,既然我们已经把 commandLine 拆分成一堆 token 了,那么判断 commandLine 是否为空,就可以改为判断 tokens 是否为空了。因为一旦更容易被处理的 tokens 拆出来了,我们就不再需要原始的 commandLine 了。把 commandLine.split(' ') 这一行移动到 if 语句的上面,保存,绿的。接着替换 if 语句的条件:
if (tokens.length) {
// ...
}
保存,哈哈,红了。我们只改了这一行,就变红了,说明问题就出在这一行。也就是说 tokens.length 和 commandLine 两个条件并不一致。什么原因?因为空字符串按空格做 split() 会得到 [''],而不是 []。所以我们针对拆分结果做一个过滤就是了:
parse(commandLine) {
let args = this.schemas.map(schema => this.getDefaultValue(schema));
let tokens = commandLine.split(' ').filter(t => t.length);
if (tokens.length) {
let flag = tokens.shift().substring(1);
let value = tokens.shift();
let schema = this.schemas.find(s => s.flag === flag);
let arg = args.find(a => a.flag === flag);
arg.value = schema.type.convert(value);
}
return new Arguments(args);
}
保存,绿了。请注意思考,我们是如何快速发现代码引入了错误的,因为:
有测试的保护。
再思考,我们是如何快速定位错误的,因为我们是:
小步前进。
好了,这段代码看起来还是比较清楚的,虽然还有些味道可以重构,不过已经不影响我们做下一个任务了。考虑到我们已经在这个任务里面待了很久了,还是继续前进吧。在那之前,别忘了,
测试代码和生产代码同等重要。
我们看看测试代码是否需要重构。很显然,又是三段重复代码,继续用前面介绍的方法抽取出公共方法。记得要小步前进哦。抽取后,相关测试用例代码如下:
it('处理布尔型参数', () => {
testSingleArgument(BooleanSchema, 'd', '-d', true);
});
it('处理字符串型参数', () => {
testSingleArgument(StringSchema, 'l', '-l /usr/logs', '/usr/logs');
});
it('处理整数型参数', () => {
testSingleArgument(IntegerSchema, 'p', '-p 8080', 8080);
});
抽取出的公共方法如下:
function testSingleArgument(schemaType, flag, commandLine, expectedValue) {
let schemas = [schemaType(flag)];
let parser = new ArgumentParser(schemas);
let result = parser.parse(commandLine);
expect(result.get(flag)).toEqual(expectedValue);
}
保存,绿的。再看看之前抽取出的那个公共方法 testDefaultValue():
function testDefaultValue(schemaType, flag, defaultValue) {
let schemas = [schemaType(flag)];
let parser = new ArgumentParser(schemas);
let commandLine = '';
let result = parser.parse(commandLine);
expect(result.get(flag)).toEqual(defaultValue);
}
两个公共方法之间同样存在重复代码,对吧,所以我们继续抽取公共方法:
function testParseArgument(schemaType, flag, commandLine, expectedValue) {
let schemas = [schemaType(flag)];
let parser = new ArgumentParser(schemas);
let result = parser.parse(commandLine);
expect(result.get(flag)).toEqual(expectedValue);
}
function testDefaultValue(schemaType, flag, defaultValue) {
testParseArgument(schemaType, flag, '', defaultValue);
}
function testSingleArgument(schemaType, flag, commandLine, expectedValue) {
testParseArgument(schemaType, flag, commandLine, expectedValue);
}
保存,绿的。不过目前 testSingleArgument() 方法比较尴尬,就做了个二传手,啥也没干。这说明什么问题?说明 testSingleArgument() 原本是更通用的存在,而 testDefaultValue() 只是其特殊情况。也就是说,原来的两个公共方法之间,不是兄弟关系,而是父子关系。所以我们可以这样:
function testSingleArgument(schemaType, flag, commandLine, expectedValue) {
let schemas = [schemaType(flag)];
let parser = new ArgumentParser(schemas);
let result = parser.parse(commandLine);
expect(result.get(flag)).toEqual(expectedValue);
}
function testDefaultValue(schemaType, flag, defaultValue) {
testSingleArgument(schemaType, flag, '', defaultValue);
}
保存,绿的。这样代码更清晰一些。好了,又是休息时间:)
(下)集在这里:http://www.uperform.cn/tdd-test-driven-development-practice-2/


{kind=link}
{kind=link}